
Traditionally, human inspectors have been the last line of defense. With years of experience and sharp eyes, they know where to look and what to feel. Yet human inspection has its limits: it’s repetitive, tiring, and sometimes unsafe. As production speed and volume continue to rise, even skilled operators can miss defects.
That’s where automation and artificial intelligence (AI) come in. The MAGICIAN project, of which this thesis is a part, aims to make inspection smarter, safer, and more reliable. Its motivation is simple: improve workplace safety for human operators while increasing production efficiency. The key may lie in teaching machines not only to see, but also to feel.
Recent studies highlight the importance of this challenge. In 2023, automakers worldwide paid approximately USD 51 billion in warranty claims, representing a significant cost burden (Mordor Intelligence, 2025). Another study found that over 27 % of quality-control costs stem from defects in exterior components (TRIGO Group, 2024), showing that even small imperfections have large financial consequences.
When seeing isn’t enough: how AI gains a new sense
Over the past decade, cameras and computer vision have become powerful tools in quality inspection. AI models can be trained to recognize scratches, dents, or paint defects with impressive accuracy. But vision has its blind spots. Some defects are subtle or hidden under certain lighting conditions. Others are more easily detected by touch than sight.
💡 Think about how a human inspector works: they don’t just look at a surface, they often run their fingers across it. The eyes catch the obvious; the hands catch the subtle.
Machines, until now, have often relied on vision alone. The result? AI can miss the defects that even a tired human fingertip would not.
Adding the sense of touch: tactile data
This is where tactile sensors come into play. These sensors provide machines with a “sense of touch.” By moving a tactile probe across a surface, tiny irregularities in pressure can be recorded as a time series; a stream of data that tells us how smooth or rough the surface feels.
Now imagine combining this tactile sense with the camera’s vision. Just like a human inspector using both eyes and hands, a machine could gain a fuller, richer understanding of the surface. The challenge, of course, is how to make sense of these very different data types and bring them together.
Our approach: bringing vision and touch together
The core objective of this research was to explore how AI can combine image data (vision) and tactile data (touch) for defect detection and localization on car body panels.
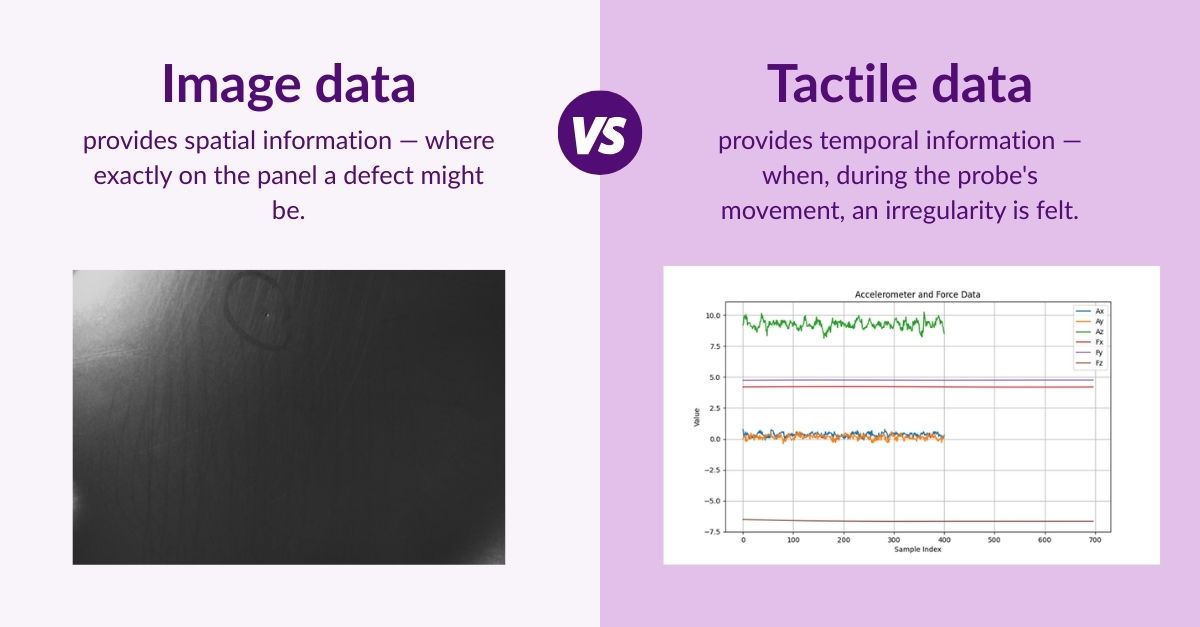
Image vs Tactile Data
The trick is to align these two streams so that they can be analyzed together. In this thesis, this was done by pairing image patches (small cropped areas of the panel surface) with time windows (segments of tactile readings). Each pair forms a “joint sample” representing both vision and touch.
These samples then serve as input for what we call fusion networks; machine learning models that combine the strengths of image and tactile data to decide: defect or no defect.
Building the fusion networks
There are many ways to combine two sources of information. In this research, we systematically explored two main strategies: early fusion and late fusion.
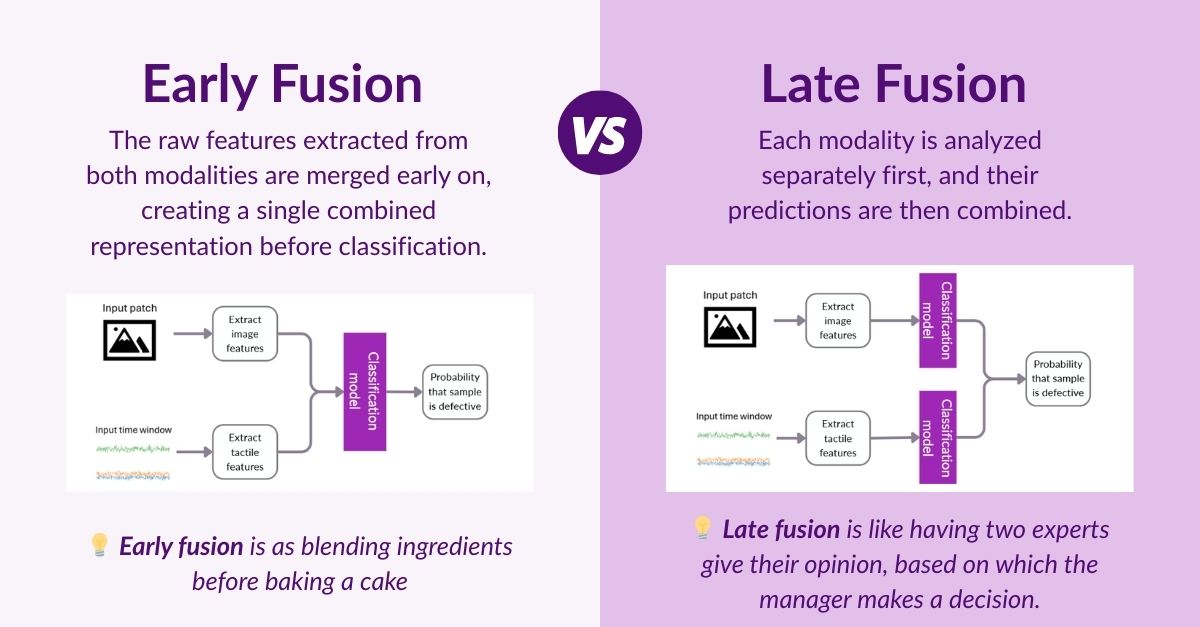
Early vs Late Fusion
For each strategy, we explored different ways of analyzing both image and tactile data. This included two main approaches: manually selecting meaningful signal characteristics based on expert knowledge, and using deep learning models that automatically learn patterns from the data.
Testing under real-world conditions
Models are only as good as the conditions they are tested under. To make the evaluation fair, we considered two scenarios: the perfect information scenario and the imperfect information scenario.
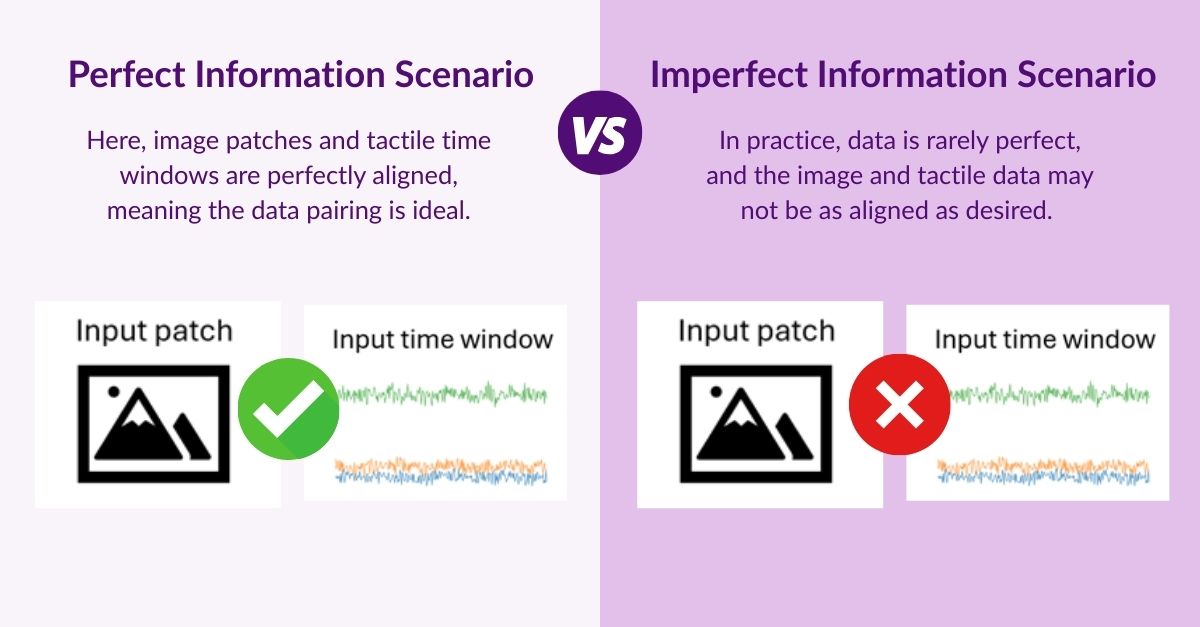
Perfect vs Imperfect Information Scenario
In the imperfect information scenario, we deliberately introduced mismatches between image-patch labels and tactile-time-window labels. These simulate errors that can occur when the pairing algorithm or the annotation process fails (for example, because of timing misalignment between sensors or incorrect label assignment), allowing us to evaluate how robust the fusion models are in a worst-case scenario.
What we found
Across both scenarios, the late fusion model that combined vision and touch achieved the strongest defect detection performance. In ideal conditions, it reached about 96%, compared to 93% for vision alone. Even in the worst-case scenario (imperfect information), the combined model still reached 94%, maintaining a clear edge over vision-only systems.
These percentages reflect how accurately the system can detect defects, with values closer to 100% meaning it correctly identifies nearly all defects while avoiding false alarms.
Even these seemingly small improvements in detection performance can have a major real-world impact. If automakers spend around USD 51 billion per year on warranty claims, and more than a quarter of all quality-control costs stem from surface and component defects, then increasing defect detection accuracy by just a few percentage points could translate into hundreds of millions of dollars saved annually through fewer faulty parts, reduced rework, and higher customer satisfaction.
Conclusion
Machines that can both see and feel open a new chapter in automated quality control. By combining tactile and image data, multimodal AI can catch defects more reliably than either approach alone.
The results suggest that multimodal defect detection is not just a technical curiosity, but a practical path forward for the manufacturing industry. The MAGICIAN project has taken an important step in proving this concept. The next steps – more data, more refinement, and broader deployment – could bring this vision from the lab to the factory floor.
About the author
This research was conducted by Stijn Craenen as part of his graduation research within the MAGICIAN project at Pipple.

