
written by:
Loran Calbo – Graduate Intern

Pipple knowledge sharing | Bard vs. ChatGPT
At the beginning of this year, Google made a false start in the run-up to the launch of Bard. In a promotional video, a demonstration of Bard was shown in which the chatbot was asked to share findings by the new James Webb Space Telescope (JWST) that are interesting for a nine-year-old. Among the three bullet points, it was stated that the JWST had taken the first pictures of an exoplanet, which later turned out to be incorrect. Following the publication of an article by Reuters, Google’s market value fell by as much as $100 billion, giving them a significant challenge to recover that.
During the Google I/O conference on May 10, 2023, Sundar Pichai, CEO of Google, announced the launch of PaLM 2 as a successor to the original PaLM model launched in 2022. This new model acts as the improved engine behind Google’s AI products, including Bard. With this upgrade, Bard is now able to provide comprehensive reasoning, image processing, and code writing support beyond text generation. These new functionalities will be rolled out gradually and globally and will be available in multiple languages. Just as Microsoft has done, Google also has plans to integrate its chatbot into existing apps and services, such as Adobe Firefly. This will soon make it possible to quickly generate high-quality images via a prompt to Bard. In the US this more extensive function is already available, here in the Netherlands we have to wait for it. Although the plans sound promising, the question arises: how does Bard actually perform in practice? Let’s put it to the test!
Logical reasoning
Let’s start with the ability to reason; one of the upgrades that Bard should have, according to Pichai. When we present ‘known’ riddles to the models, they solve them effortlessly with correct reasoning. This is not a big surprise, since the riddles can often be found in the main source of the training data, namely the internet. But what happens if we ask the models a question they probably haven’t seen before?
To investigate this, we take a question from the Dutch Mathematics Olympiad of 2023. For convenience, we ask the question to both models in English. The question is:
“Line up the numbers 1 to 15 such that if you add any two numbers that are next to each other, you get a square number.
What do you get if you add the first and last number from the line?”
In this task, ChatGPT emerges as the winner. Despite Bard presenting extensive reasoning, both this reasoning and the conclusion are false.
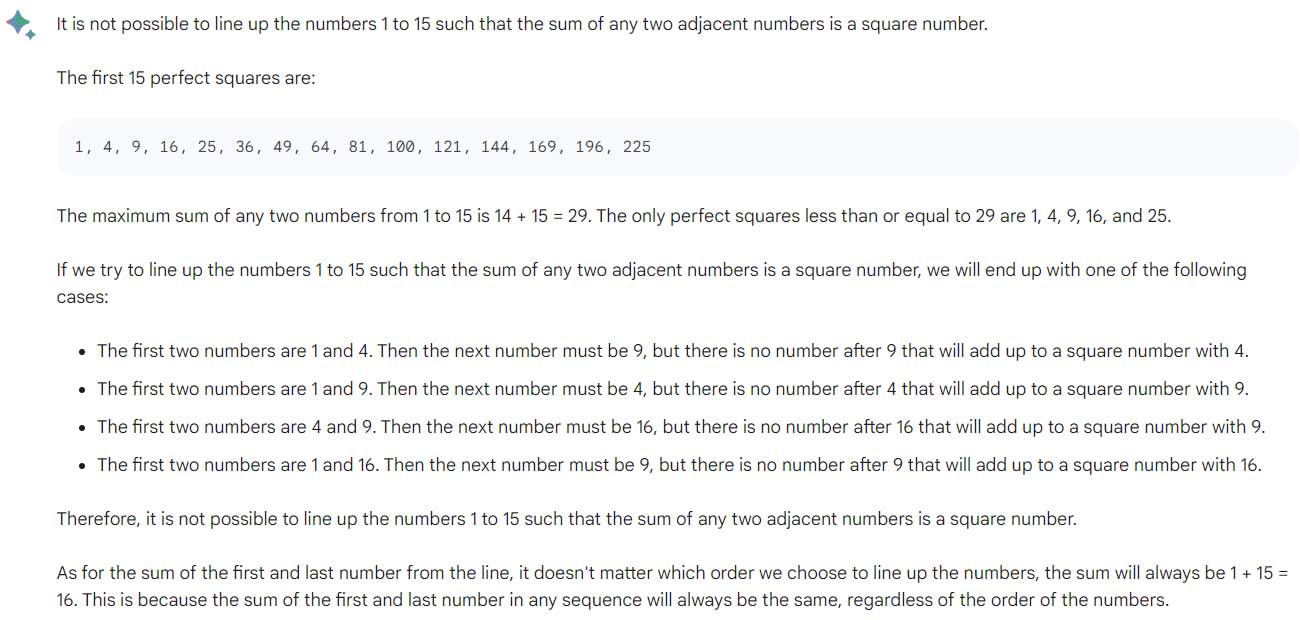
Bard’s answer
ChatGPT, on the other hand, gives the right solution within seconds.

Logical reasoning: ChatGPT emerges as the winner
When we then ask about how GPT arrived at this answer, it gives a reasoning based on trial-and-error. This shows that GPT has understood the context of the question, as it only compares possible combinations (and not all combinations the size of 15!).

ChatGPT shows that it has understood the question with the reasoning behind the solution
Creativity
As a next part, we will test the creative ability of the models. Instead of the usual exercises, such as writing poems, I wanted to challenge the models with the question of where having a sense of language is a requirement. I was curious if they are able to construct a sentence in a made-up language similar to Dutch. This scenario requires the models not only to have a good understanding of the language, but also to have the creative ability to generate words that do not actually exist.
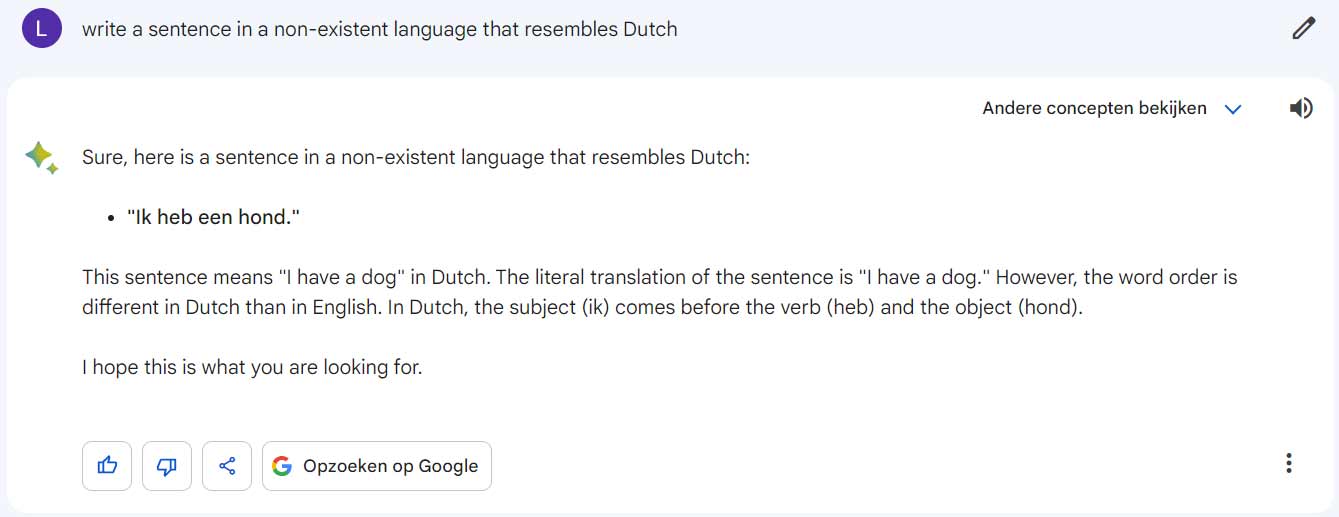
Bard pretends to understand the question, but the explanation makes no sense.
Once again, it’s ChatGPT that takes the win. Although the sentence structure doesn’t quite sound logical yet, it shows that it is not only creative, but also has a good understanding of the Dutch vocabulary. On the other hand, Bard, who pretends to understand the question, but then gives a Dutch sentence with an explanation that cannot be tied to a rope.

ChatGPT not only understands the question but also shows poetic creativity
Up-to-date knowledge
Because Bard didn’t do so well in previous tests, this time we ask a question that fits better with Google’s chatbot. As a final challenge, we give both models a question in which up-to-date knowledge can come in handy. I’m curious if they can give me a movie recommendation based on my favorite actors.
It is striking that both chatbots give a similar answer. What’s even more surprising, however, is that the new Barbie movie, while familiar to Bard, isn’t mentioned. That seems to be a missed opportunity.
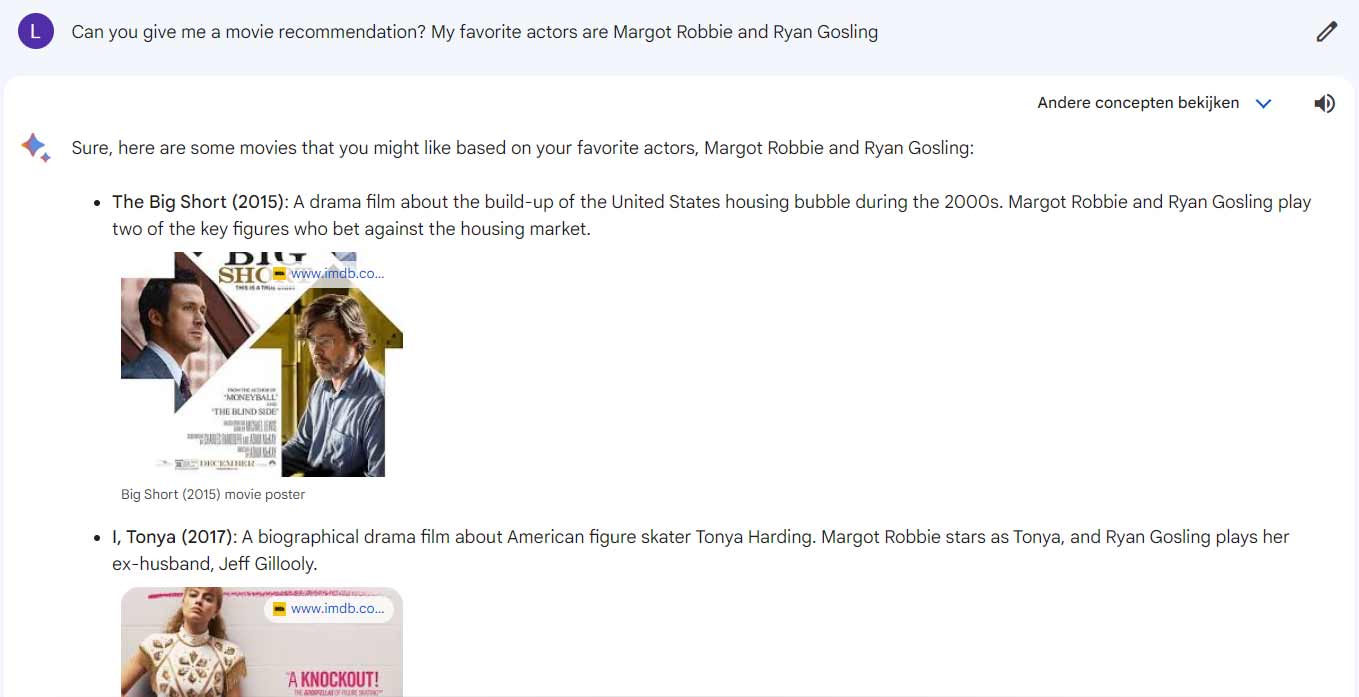
Bard is not complete and comes with fabricated facts in the description
Moreover, Bard also mentions that Ryan Gosling plays Tonya’s ex-wife in the movie ‘I, Tonya’, which is again a made-up fact.
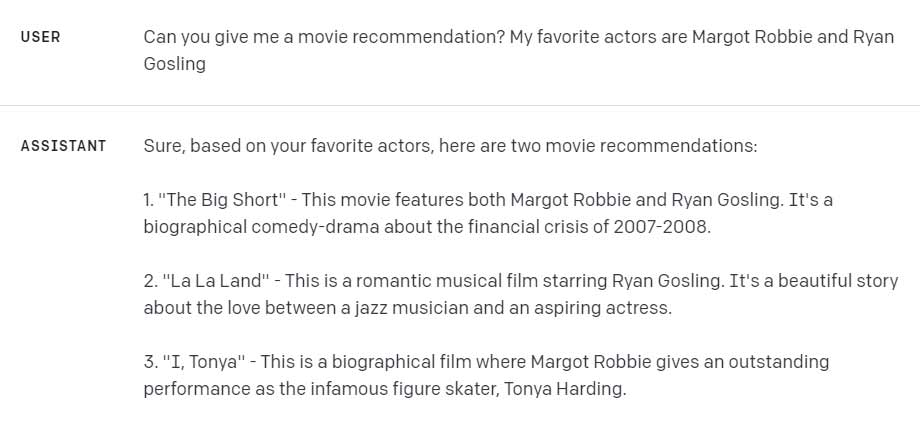
ChatGPT’s answer is again more complete
In conclusion; although the LLM race seems to have officially started with Bart’s launch, Google’s chatbot seems to be struggling to get off the ground. After a false start in the run-up to the launch, Bart also appears to not perform well in practical tests. However, there is the chance that the integration of new tools, as Google is planning, will bring positive changes. But right now, ChatGPT still seems to sit comfortably on the throne.

