Vanderlande wants to become more and more data-driven and an important condition for this is the easy access of data. Pipple helped them with the foundation: a suitable way to develop data products on the data platform. This enables Vanderlande to access data easily and company-wide.
Decentralized Data Platform
Data mesh is a way to organize and manage data decentralized, which strengthens collaboration, which in turn creates extra added value for organizations. So one of the spearheads of data mesh is that it is a decentralized model, which means that there is no central authority that manages the data. This provides the advantage that different teams and departments have easier access to the data and that there are fewer restrictions on the sharing and use of data.
Another advantage of data mesh is that it offers a holistic approach to managing data. Instead of managing data as a separate entity, data mesh focuses on embedding data into an organization’s processes and practices. This can help to integrate data more effectively into the daily work of an organization and to maximize the value of data.
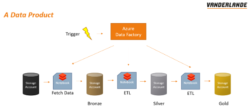
Figure 1: The standard structure of a data product within Vanderlande, from left to right the quality and value of the data increases
Why data mesh within Vanderlande?
The reason for our implementation of data mesh was the need for a more flexible and collaborative way to manage and use data. We noticed that our current way of managing data had limitations in terms of sharing and using data between different teams and departments. Moreover, it was difficult to effectively integrate data into our daily work processes and to maximize the value of data for our organization. Data mesh is a good way to address these challenges and to strengthen our data infrastructure.
Vanderlande needed knowledge about developing data products in a data mesh. That’s why they called in Pipple. Consultant Geert Jongen knew what it takes to develop good quality data products. He helped us make choices in tooling and infrastructure. In the end, a combination of Databricks, Azure Data Factory and Azure Data Lake Storage Gen 2 was chosen. In the meantime, a team of three Pippelaars honed the skills and techniques of the teams that will build and maintain the data products. The existing colleagues from Vanderlande mainly had experience in BI & Analyst tooling. Through peer programming, they were quickly trained on-the-job to become full-fledged data-product developers.
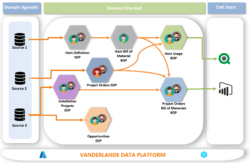
Figure 2: In the Datamesh, the data is transformed from domain agnostic to domain-specific data products. The end user can choose which datasets are needed to achieve the goal.
Collaboration with Pipple
What Vanderlande likes about working with Pipple is flexibility. “Typically, you see agencies have a number of solutions on the shelf, to which they ideally translate the client’s problem. Fortunately, that was not the case in Pipple’s case.” Kerstens is also pleased with the way Pipple intervened in the organization. “It never felt like a separate club within Vanderlande. That was because they never told us how to do it, but stood next to us. With their technical edge and the organizational knowledge of our employees, we had access to the best of both worlds.”
The result
At the time of writing, more than 100 data products have already been defined within Vanderlande and a large part of them have been developed. The products are already used in various domains, which have been able to carry out analyses that were previously impossible. For example, it has already led to crucial insights into their goods flows for Supply, for Tax to a collaboration with the Dutch tax authorities and within Technology to a very detailed Bill of Materials dataset, with which complex analyses have been made possible.


